




In the previous entry in this blog series, we discussed healthcare datasets, their limitations, and how that impacts the practice of machine learning. For this entry, let’s assume we have access to comprehensive healthcare data and the technical capability to build AI-based solutions. How should we measure the value that AI brings?
Evaluation of US healthcare more broadly has been a prominent topic for decades. More recently, value-based programs have been codified. Beginning in 2008 and implemented since 2012, sweeping healthcare reforms were introduced that incentivized better outcomes, lower costs, safer practices, and increased transparency. Notably, particular scenarios were consistently associated with high-costs and/or poor quality care, including end-stage renal disease, patients who acquire new conditions while in hospital, and patients who are readmitted to the hospital soon after being previously discharged. Specific assessment rules were defined for each of these scenarios. For example, readmission rate was set as the percentage of discharged patients with unplanned readmission within 30 days of initial admission. With these metrics in-hand, providers across the country have comparable numbers that they can use to assess whether changes in their practices move them in the right direction.
Defining and then optimizing metrics is an example of what machine learning (ML) folks call “objective functions.” They could alternatively be referred to as loss, fitness, cost, regret, or utility functions, but let’s avoid using any of these words any more than we already have this year. Algorithms really don’t do well with nuance. To ensure ML is working to produce value, we must define objectives that precisely describe what value is. It sounds easy but isn’t.
AI responses are limited; you must ask the right questions
Objectives in healthcare usually fall into two categories: Human-like reasoning and statistically-sound reasoning. An example of how these differ is between what a doctor would prescribe and what they should prescribe. Humans (and other species!) are capable of reasoning beyond even super-computer understanding, such as identifying objects in images, or understanding language even when the only rule is there are no rules. Conversely, statistical approaches can make inferences on datasets vaster than our biological confines allow. Knowing whether your objectives lie in replicating human-like reasoning or statistically-sound reasoning is crucial for achieving valuable solutions.
We refer to AI solutions that aim to replicate human-like behavior as “expert systems.” This is essentially job automation, which in an overburdened healthcare system is desirable. For example, my group worked to automate both the identification and the quantification of tumors in biopsy images, much like our dangerously short supply of pathologists would do. Identification and quantification tools both aim to maximize agreement between automated and human annotations, but their goals are different: One is like asking if a picture is of a cat, and the other is like asking to locate all the cats in a picture. Their objective functions are also distinct: For identification annotations, an easily-understood metric of success may be the percentage of samples accurately classified (although better variants exist like F1-score or Lift for uneven datasets). For quantification annotations, we aim to maximize the area overlapping between automated and human-annotated regions while minimizing area that doesn’t overlap (e.g., dice score). Whatever the metric being optimized, near-enough approximations of humans that are more consistent, cheaper, or more scalable are sufficient to drive value.
 Example of maximizing agreement between humans and machines: Human pathologists marked tumor regions in blue circles, machine-vision automatically annotated regions in orange. Link to abstract presented at SITC2019.
Example of maximizing agreement between humans and machines: Human pathologists marked tumor regions in blue circles, machine-vision automatically annotated regions in orange. Link to abstract presented at SITC2019.
Heigh-ho, it’s off to work in the data mines we go
AI solutions that aim to derive novel insights from statistical approaches are known as “data mining,” and these are much harder to assess for their value. Data mining is not new: We humans have an embarrassingly small cache and can only keep about seven numbers in our heads, so using systems to track figures is as old as civilization itself. What has made data mining a juggernaut in the AI industry is the massive advancement in computer processors, giving us the ability to crunch billions of figures simultaneously. Methods to perform data mining are numerous, and the ways to assess the results are equally varied. For example, clustering algorithms that attempt to group objects together can be assessed by how closely cases are grouped (e.g., davies-bouldin score), or how well groups are separated (e.g., silhouette coefficient), or how well a given grouping agrees with other groupings (e.g., rand-index). There is no shortage of objective functions for data mining solutions, but none alone are sufficient to prove value in healthcare.
Ultimately the gold-standard way to assess new clinical strategies is by trialing them and demonstrating superiority over an existing approach (which may be doing nothing at all). In some ways, clinical trials are analogous to the A/B tests employed in software engineering, albeit with more deference paid to ethical concerns. Prefixes like “randomized double-blind placebo-controlled parallel-group multi-center prospective trial” just describe all the confounding variables the trial designers removed to make the statistics more sound, but they are still just comparing strategies. The metric most commonly used in clinical trials is the proportional hazard, which is basically the likelihood over time that a patient has a bad outcome (with some added fanciness for including patients that leave the trial). The relative risk of strategy A vs. strategy B is simply their Hazard Ratio: If A/B < 1, then go with A.
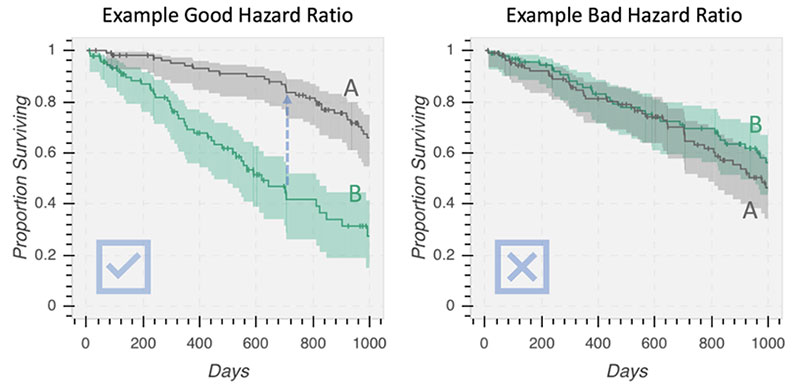 Examples of good and bad hazard ratios, as shown in Kaplan-Meier plots. The Y-axis is the proportion of patients that have yet to have a bad outcome, so the higher the line stays across time, the better the strategy. In the left plot, the relative risk to group A is far less than group B, suggesting strategy A is superior. In the right plot, the relative risk to group A and B are about the same, so there is no benefit of strategy A over B.
Examples of good and bad hazard ratios, as shown in Kaplan-Meier plots. The Y-axis is the proportion of patients that have yet to have a bad outcome, so the higher the line stays across time, the better the strategy. In the left plot, the relative risk to group A is far less than group B, suggesting strategy A is superior. In the right plot, the relative risk to group A and B are about the same, so there is no benefit of strategy A over B.
That last paragraph describing minimizing hazard ratios is also an objective function; however, minimizing hazard ratios is an exceptionally elusive objective for AI solutions. There are two ways to trial AI solutions: 1. Prospectively, meaning AI selects the strategy, or 2. Retrospectively, wherein previously administered strategies are re-analyzed using an AI tool. Recall that building AI using machine learning requires training and testing phases. Obviously, training and testing AI prospectively is unethical: No one is comfortable treating patients randomly until algorithms have enough data to make decisions. Training algorithms on retrospective data and testing them prospectively is a reasonable goal. However, this remains a futuristic one. The medical community is ethically bound to retain human clinicians as the ultimate decision makers if only to avoid diagnoses of having “network connectivity problems.” Even training retrospectively and testing retrospectively is a frontier for AI in healthcare: Successes are lauded in top-tier journals, such as suggesting reduction of chemotherapy using breast cancer risk-scores, or optimizing antisepsis therapy, or as an example from my group, we demonstrated combining drug target assays to better predict response. The value of these as standalone tools to reduce risk has not been (and probably will not be) shown prospectively.
AI should spark joy for doctors
In the near-term, the value of AI-driven novel insights is in decision-support. AI will not replace clinicians any time soon but instead will condense vast amounts of data down to human scale understanding for their use. Whether that’s by using databases to suggest treatment options, generating informative biomarkers, or directly providing risk assessments, the same goal applies: If incorporating these tools is practice-changing, then they are valuable.
Ultimately AI solutions, whether expert-systems or from data mining, are similar to any other medical technology: As they improve, we should be provided with better, safer, cheaper, more accessible, or more consistent care. The excitement surrounding AI in healthcare is the promise that it is a vehicle to accelerate our pace toward these goals. I implore everyone involved in pressing this accelerator to make sure they’re pointed in the right direction first.


